Two papers have been accepted to IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) 2023. ICASSP’s main theme this year will be “Signal Processing in the Artificial Intelligence era,” promoting the creative synergy between signal processing and machine learning.
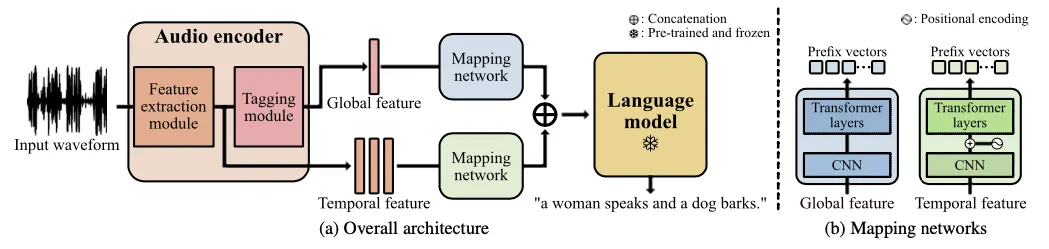
Title: Prefix Tuning for Automated Audio Captioning
Authors: Minkyu Kim*, Kim Sung-Bin*, Tae-Hyun Oh (*equal contribution)
Audio captioning aims to generate text descriptions from environ- mental sounds. One challenge of audio captioning is the difficulty of the generalization due to the lack of audio-text paired training data. In this work, we propose a simple yet effective method of dealing with small-scaled datasets by leveraging a pre-trained lan- guage model. We keep the language model frozen to maintain the expressivity for text generation, and we only learn to extract global and temporal features from the input audio. To bridge a modality gap between the audio features and the language model, we employ map- ping networks that translate audio features to the continuous vectors the language model can understand, called prefixes. We evaluate our proposed method on the Clotho and AudioCaps dataset and show our method outperforms prior arts in diverse experimental settings.
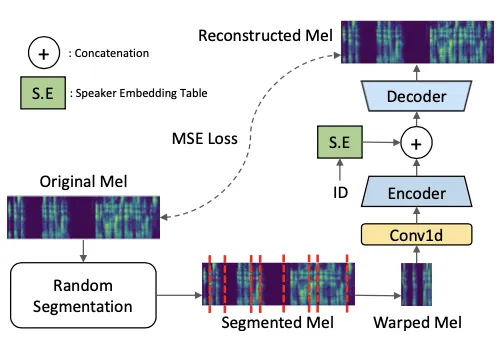
Title: Unsupervised Pre-training for Data-Efficient Text-to-Speech on Low Resource Languages
Authors: Seongyeon Park*, Myungseo Song*, Bohyung Kim, Tae-Hyun Oh (*equal contribution)
Neural text-to-speech (TTS) models can synthesize natu- ral human speech when being trained on large amounts of transcribed speech. However, collecting such large-scale transcribed data is expensive. In this paper, we propose an unsupervised pre-training method for a sequence-to-sequence TTS model by leveraging large untranscribed speech data, and whereby we can remarkably reduce the amount of paired transcribed data required to train the model for the target down-stream TTS task. The main idea is to pre train the model to reconstruct de-warped mel-spectrograms from warped ones, which may allow the model to learn proper temporal assignment relation between input and output se- quences. In addition, we propose a data augmentation method to further improve the data-efficiency in fine tuning. We empirically demonstrate the effectiveness of our proposed method in low-resource language scenarios, achieving out- standing performance compared to competing methods.