 Three papers have been accepted to ECCV 2022
Three papers have been accepted to ECCV 2022
European Conference on Computer Vision (ECCV) is one of the major international conferences on computer vision and related areas. (Accept. rate 28.4%)
Title: CLIP-Actor: Text-Driven Recommendation and Stylization for Animating Human Meshes
Authors: Kim Youwang* (POSTECH), Kim Ji-Yeon* (POSTECH), Tae-Hyun Oh (POSTECH)
* denotes the equal contribution
CLIP-Actor is an automated system for generating an animatable 4D human avatar, only from a single natural language sentence. CLIP-Actor synthesizes visually plausible texture with dynamic, text-conforming motion. Our novel Hierarchical multi-modal motion recommendation suggests the textually, visually matching human motion. Also, proposed Decoupled optimization of Neural Style Field enables realistic and vivid texture generation for the recommended human motion.
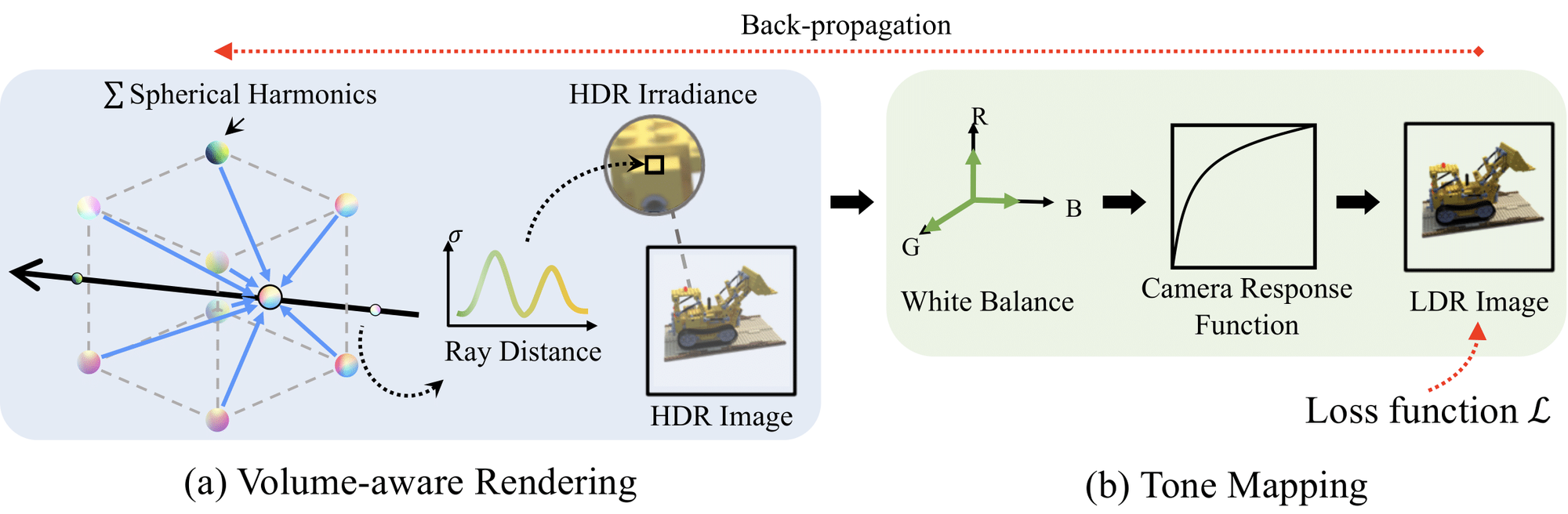
Title: HDR-Plenoxels: Self-Calibrating High Dynamic Range Radiance Fields
Authors: Kim Jun-Seong* (POSTECH), Kim Yu-Ji* (POSTECH), Moon Ye-Bin (POSTECH), Tae-Hyun Oh (POSTECH)
* denotes the equal contribution
We propose High Dynamic Range Plenoxels (HDR-Plenoxels) that learns the plenoptic function of the 3D scene from a comprehensive understanding of 3D information, physical radiance field, and varying camera settings inherent in 2D low dynamic range (LDR) images. Our voxel-based volume rendering pipeline reconstruct HDR radiance fields from a LDR images of varying camera settings in an end-to-end manner. To deal with various cameras in real-world scenarios, we introduce a tone mapping module that can be easily attached to most volume rendering models. The model is optimized to render the LDR images from the HDR radiance field during the tone mapping stage, which is designed based on the analysis of the digital in-camera imaging pipeline. Our experiments show that our method can express the HDR novel view from LDR images even with various cameras.
Title: Cross-Attention of Disentangled Modalities for 3D Human Mesh Recovery with Transformers
Authors: Junhyeong Cho (POSTECH), Kim Youwang (POSTECH), Tae-Hyun Oh (POSTECH)
We propose an efficient transformer for 3D human pose and mesh reconstruction from a single image, called FastMETRO. We identify the performance bottleneck in the encoder-based transformers is caused by the token design which introduces high complexity interaction between input tokens. We disentangle the interaction via an encoder-decoder architecture, which allows our model to demand much fewer parameters and shorter inference time. In addition, we impose the prior knowledge of human body’s morphological relationship via attention masking and upsampling operations, which leads to faster convergence with improved accuracy. FastMETRO improves the Pareto-front of accuracy and efficiency, and clearly outperforms image-based methods on Human3.6M and 3DPW.
