 Eight papers have been accepted to CVPRw 2023
Eight papers have been accepted to CVPRw 2023
VCAD: Vision-Centric Autonomous Driving
Title: MinDVPS: Minimal Model for Depth-aware Video Panoptic Segmentation
Authors: Kim Ji-Yeon (POSTECH), Oh Hyun-Bin (POSTECH), Dahun Kim (Google Research), Tae-Hyun Oh (POSTECH)
Depth-aware Video Panoptic Segmentation (DVPS) is one of the complicated multi-task learning problems that jointly tackles video panoptic segmentation and depth estimation in a single model. Existing works are typically composed of task-specialized heads, including respective segmentation heads for things and stuff, global and instance depth map heads, and a tracking head, and are trained with consecutive video frames. Increasing the complexity of modules, losses, and data batch may lead to sensitive performance against training or hyper-parameter configurations. In this work, we attempt to seek for minimal architecture and configurations for the DVPS task. Motivated by the past success of the per-frame semantic segmentation methods in the video semantic segmentation field, we propose MinDVPS, a simple and minimal model that does not require any temporal annotations during training and the tracking module. Instead of using extra tracking modules, our model utilizes the learnable embeddings, i.e., queries, to track the objects frame-by-frame in online fashion. We also demonstrate the effectiveness of our design choice by achieving the state-of-the-art performances on Cityscapes-DVPS.

Workshop on Foundation Models: 1st Foundation Model Challenge
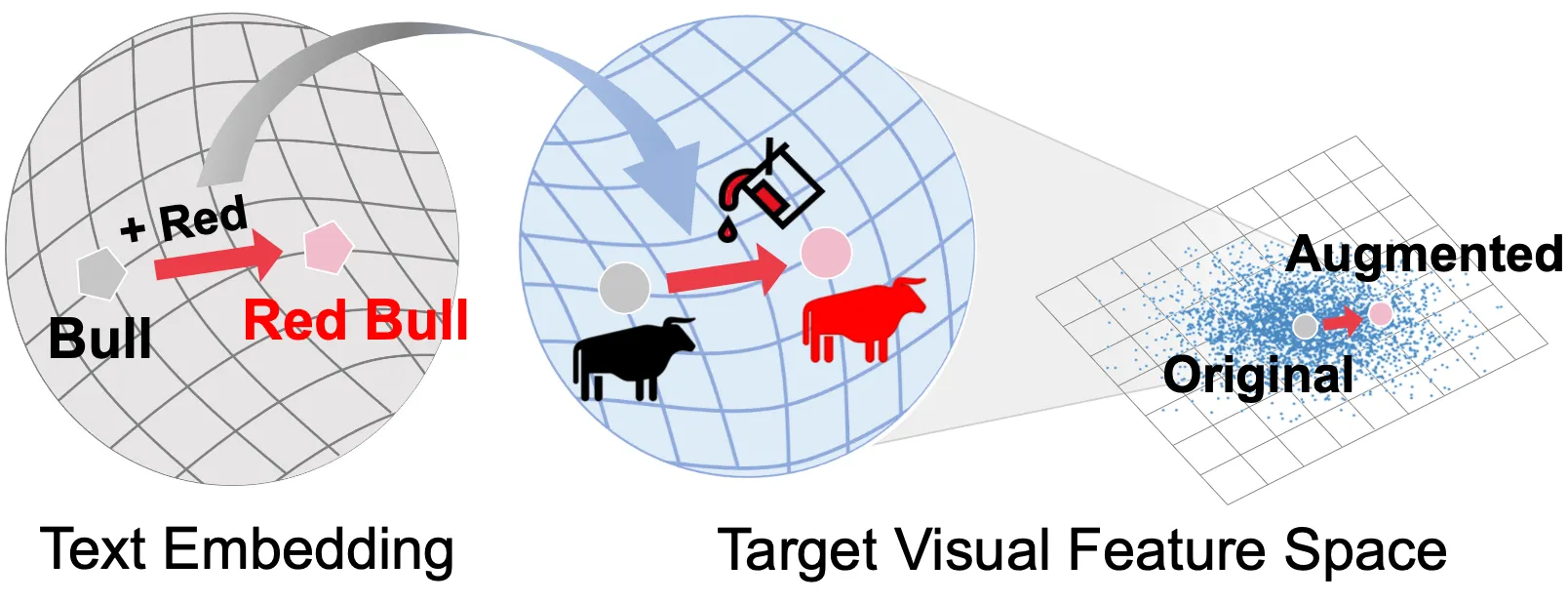
Title: Enriching Visual Features via Text-driven Manifold Augmentation
Authors: Moon Ye-Bin (POSTECH), Jisoo Kim (Ewha Womans University), Hongyeob Kim (uvilab), Kilho Son (Microsoft Azure), Tae-Hyun Oh (POSTECH)
Recent label mix-based augmentation methods have shown their effectiveness in generalization despite their simplicity, and their favorable effects are often attributed to semantic-level augmentation. However, we found that they are vulnerable to highly skewed distribution, because scarce data classes are rarely sampled for inter-class perturbation. We propose a text-driven manifold augmentation that semantically enriches visual feature spaces, regardless of data distribution. Our method augments visual data with intra-class semantic perturbation by exploiting easy-to-understand visually mimetic words, i.e., attributes. To this end, we bridge between the text representation and a target visual feature space, and propose an efficient vector augmentation. Our experiments demonstrate that the proposed method is powerful in scarce samples with class imbalance. Note that this research is a work in progress.
Workshop on Vision-based InduStrial InspectiON (VISION)
Title: Revisiting Deep Video Motion Magnification for Real-time Applications
Authors: Hyunwoo Ha* (POSTECH), Oh Hyun-Bin* (POSTECH), Kim Jun-Seong (POSTECH), Kwon Byung-Ki (POSTECH), Kim Sung-Bin (POSTECH), Ji-Yun Kim (POSTECH), Sung-Ho Bae (Kyung Hee University),Tae-Hyun Oh (POSTECH)
* denotes the equal contribution
The state-of-the-art learning-based approach succeeds in modeling the motion magnification problem and achieves better quality against conventional techniques. However, it still does not meet the demand of real-time Full High Definition (Full-HD) video processing, which distracts to be used in diverse applications such as safety monitoring and medical imaging. We first identify the unnecessary components in the state-of-the-art learning-based model using learning-to-remove method. Then, we search the approximate optimal hyperparameters in the reduced search space and reassemble the architecture. Our real-time deep motion magnification model has 4.5x fewer FLOPs and is 3x faster than the prior art while maintaining comparable results and sub-pixel motion performance. Further, our model has better noise characteristics than any other previous works.

Sight and Sound
Title: Sound to Visual Scene Generation by Audio-to-Visual Latent Alignment
Authors: Kim Sung-Bin (POSTECH), Arda Senocak (KAIST), Hyunwoo Ha (POSTECH), Andrew Owens (University of Michigan), Tae-Hyun Oh (POSTECH)
* This work is presented in CVPR 2023
* This work is presented in CVPRw 2023 (AI for Content Creation)
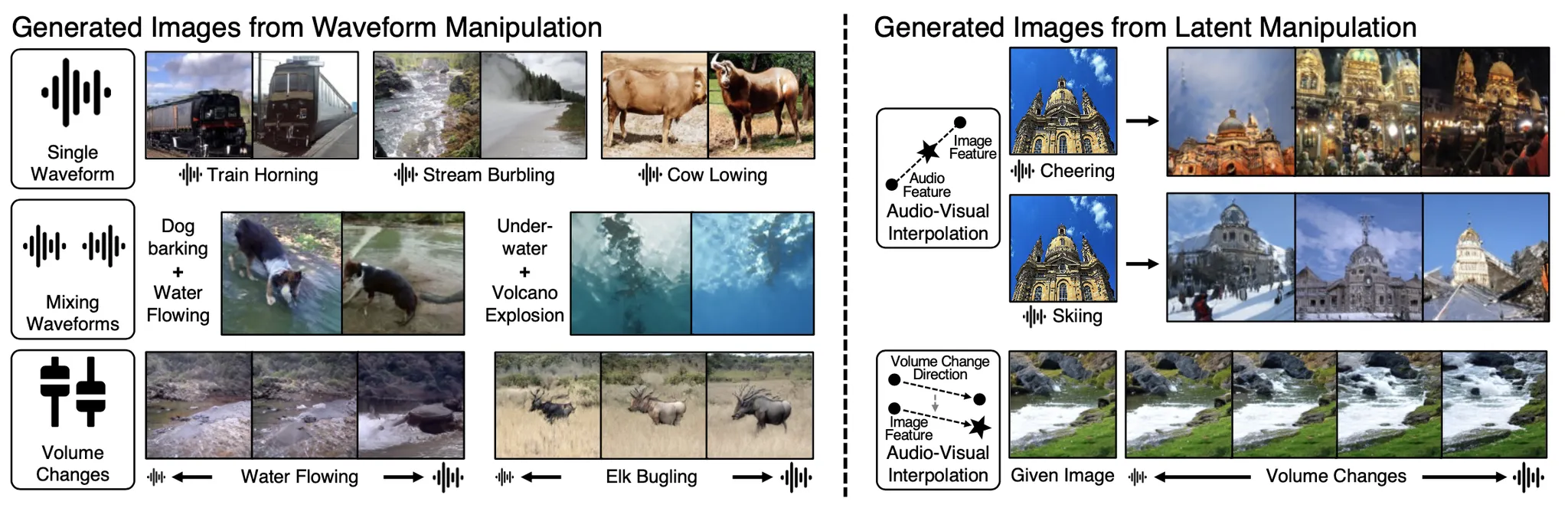
How does audio describe the world around us? In this paper, we explore the task of generating an image of the visual scenery that sound comes from. However, this task has inherent challenges, such as a significant modality gap between audio and visual signals, and incongruent audio-visual pairs. We propose a self-supervised model by scheduling the learning procedure of each model component to associate these heterogeneous modalities despite their information gaps.The key idea is to enrich the audio features with visual information by learning to align audio to visual latent space. Thereby, we translate input audio to visual feature, followed by a powerful pre-trained generator to generate an image.
We further incorporate a highly correlated audio-visual pair selection method to stabilize the training. As a result, our method demonstrates substantially better quality in a large number of categories on VEGAS and VGGSound datasets, compared to the prior arts of sound-to-image generation. Besides, we show the spontaneously learned output controllability of our method by applying simple manipulations on the input in the waveform space or latent space.
3DMV: Learning 3D with Multi-View Supervision
Title: STREAM: Spatio-Temporally Consistent Face Mesh Reconstruction on Videos
Authors: Kim Youwang (POSTECH), Lee Hyun* (POSTECH), Kim Sung-Bin* (POSTECH), Suekyeong Nam (KRAFTON), Janghoon Ju (KRAFTON), Tae-Hyun Oh (POSTECH)
* Denotes the equal contribution
We propose STREAM, a 3D parametric face reconstruction method on videos with spatio-temporal consistency. We design a novel optimization method that fits the neural re-parameterized 3D face meshes on videos. By leveraging spatio-temporal cues inherent in face videos, we develop novel multi-view and temporal consistency losses. We harmonize our spatio-temporal losses with a 2D landmark loss, and fit the per-view/-frame accurate and consistent face meshes on videos. The results show that our method nicely infuses spatio-temporal consistency into reconstructed 3D faces with favorable reconstruction accuracy.

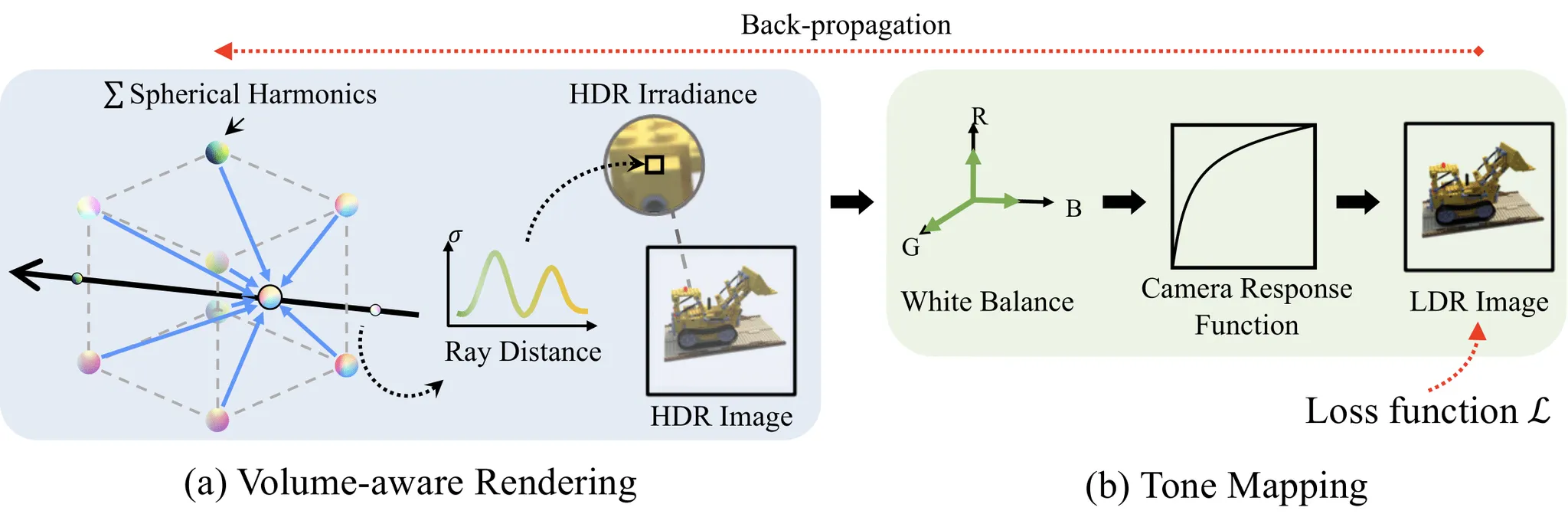
Title: HDR-Plenoxels: Self-Calibrating High Dynamic Range Radiance Fields
Authors: Kim Jun-Seong* (POSTECH), Kim Yu-Ji* (POSTECH), Tae-Hyun Oh (POSTECH)
* Denotes the equal contribution
* This work was presented in ECCV 2022
We propose High Dynamic Range Plenoxels (HDR-Plenoxels) that learns the plenoptic function of the 3D scene from a comprehensive understanding of 3D information, physical radiance field, and varying camera settings inherent in 2D low dynamic range (LDR) images. Our voxel-based volume rendering pipeline reconstruct HDR radiance fields from a LDR images of varying camera settings in an end-to-end manner. To deal with various cameras in real-world scenarios, we introduce a tone mapping module that can be easily attached to most volume rendering models. The model is optimized to render the LDR images from the HDR radiance field during the tone mapping stage, which is designed based on the analysis of the digital in-camera imaging pipeline. Our experiments show that our method can express the HDR novel view from LDR images even with various cameras.
AI for Content Creation
Title: CLIP-Actor: Text-Driven Recommendation and Stylization for Animating Human Meshes
Authors: Kim Youwang* (POSTECH), Kim Ji-Yeon* (POSTECH), Tae-Hyun Oh (POSTECH)
* Denotes the equal contribution
* This work was presented in ECCV 2022
CLIP-Actor is an automated system for generating an animatable 4D human avatar, only from a single natural language sentence. CLIP-Actor synthesizes visually plausible texture with dynamic, text-conforming motion. Our novel Hierarchical multi-modal motion recommendation suggests the textually, visually matching human motion. Also, proposed Decoupled optimization of Neural Style Field enables realistic and vivid texture generation for the recommended human motion.