

Information about computer vision and machine learning academic field
* Top-tier conferences
: CVPR, ICCV, ECCV, NeurIPS (NIPS), ICML, and ICLR are considered as high prestigious and top-tier conferences, which deem to have larger impacts than most SCI journals. According to Google scholar metrics, all these conferences are listed in the top 100 in all academic fields. Out of them, CVPR is the 5th rank (Science and Nature are the 1st and 3rd ranked) among all academic fields,
In terms of the acceptance rate, oral presentations are about <4% and poster presentations about 25%, i.e., highly competitive.
* Top-tier journals
: IEEE TPAMI has the highest impact factor across all computer science categories. As of 2021, the impact factor of TPAMI is 24.314.
2024
Conferences
The Devil is in the Details: Simple Remedies for Image-to-LiDAR Representation Learning
Asian Conference on Computer Vision (ACCV) 2024
Wonjun Jo, Kwon Byung-Ki, Kim Ji-Yeon,
Hawook Jeong, Kyungdon Joo, Tae-Hyun Oh
MeTTA: Single-View to 3D Textured Mesh Reconstruction with Test-Time Adaptation
Kim Yu-Ji, Hyunwoo Ha, Kim Youwang, Jaeheung Surh, Hyowon Ha†, Tae-Hyun Oh†

Learning-based Axial Video Motion Magnification
Kwon Byung-Ki, Oh Hyun-Bin, Kim Jun-Seong, Hyunwoo Ha, Tae-Hyun Oh
BEAF: Observing Before-AFter Changes to Evaluate Hallucination in Vision-language Models
Moon Ye-Bin*, Nam Hyeon-Woo*, Wonseok Choi, Tae-Hyun Oh (*equal contribution)
MultiTalk: Enhancing 3D Talking Head Generation Across Languages with Multilingual Video Dataset
Kim Sung-Bin*, Lee Chae-Yeon*, Gihun Son*, Oh Hyun-Bin, Janghoon Ju, Suekyeong Nam, Tae-Hyun Oh (*equal contribution)
Enhancing Speech-Driven 3D Facial Animation with Audio-Visual Guidance from Lip Reading Expert
Han EunGi*, Oh Hyun-Bin*, Kim Sung-Bin, Corentin Nivelet Etcheberry, Suekyeong Nam, Janghoon Ju, Tae-Hyun Oh (*equal contribution)

SMILE: Multimodal Dataset for Understanding Laughter in Video with Language Models
Lee Hyun*, Kim Sung-Bin*, Seungju Han, Youngjae Yu, Tae-Hyun Oh (*equal contribution)
* Presented in Workshop on AV4D: Visual learning of sounds in spaces, in conjunction with ICCV 2023.
* Presented in Workshop on MMFM: Multi-Modal Foundation Models, in conjunction with ICCV 2023.
Paint-it: Text-to-Texture Synthesis via Deep Convolutional Texture Map Optimization and Physically-Based Rendering
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2024 [Project Page] [arXiv] [Code]
* Presented in AI for Content Creation Workshop (AI4CC), in conjunction with CVPR 2024
* Presented in AI for 3D Generation (AI3DG), in conjunction with CVPR 2024
Kim Youwang, Tae-Hyun Oh, Gerard Pons-Moll

CAS: A Probability-Based Approach for Universal Condition Alignment Score
Chunsan Hong, ByungHee Cha, Tae-Hyun Oh
* Accepted as a spotlight paper (<5% acceptance rate)

Noise Map Guidance: Inversion with Spatial Context for Real Image Editing
Hansam Cho, Jonghyun Lee, Seoung Bum Kim, Tae-Hyun Oh*, Yonghyun Jeong*
FPRF: Feed-Forward Photorealistic Style Transfer of Large-Scale 3D Neural Radiance Fields
GeonU Kim, Kim Youwang, Tae-Hyun Oh
LaughTalk: Expressive 3D Talking Head Generation with Laughter
Kim Sung-Bin, Lee Hyun, Da hye Hong, Suekyeong Nam, Janghoon Ju, Tae-Hyun Oh
Object-Centric Domain Randomization for 3D Shape Reconstruction in the Wild
IEEE Conference on Computer Vision and Pattern Recognition (CVPR workshop) 2024
(Workshop on Foundation Models) [Project Page] [arXiv]
Junhyeong Cho, Kim Youwang, Hunmin Yang, Tae-Hyun Oh

MemBench: Memorized Image Trigger Prompt Dataset for Diffusion Models
Chunsan Hong, Tae-Hyun Oh, Minhyuk Sung

An Efficient and Effective Sea Turtle Detection Using Positioning Enhancement Module
The International Workshop on Intelligent Systems 2024
Muhamad Dwisnanto Putro, Dirko Ruindungan, Tae-Hyun Oh, Ilyong Chun, Syahputra Rendy, Vecky Poekoel
Journals
Computational Discovery of Microstructured Composites with Optimal Strength-Toughness Trade-Offs
Beichen Li, Bolei Deng, Wan Shou, Tae-Hyun Oh, Yuanming Hu, Yiyue Luo, Liang Shi, Wojciech Matusik

A Large-Scale 3D Face Mesh Video Dataset via Neural Re-parameterized Optimization
Kim Youwang, Lee Hyun*, Kim Sung-Bin*, Suekyeong Nam, Janghoon Ju, Tae-Hyun Oh

Factorized Multi-Resolution HashGrid for Efficient Neural Radiance Fields: Execution on Edge-Devices
Kim Jun-Seong*, Mingyu Kim*, GeonU Kim, Tae-Hyun Oh†, Jin-Hwa Kim†
Uni-DVPS: Unified Model for Depth-Aware Video Panoptic Segmentation
Kim Ji-Yeon, Oh Hyun-Bin, Kwon Byung-Ki, Dahun Kim, Yongjin Kwon, Tae-Hyun Oh
* Presented in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2024 (Selected as Oral presentation)
* Asian Federation of Computer Vision (AFCV) Best Paper Award, from Korea Robotics Conference (KRoC) 2024
A Unified Framework for Unsupervised Action Learning via Global-to-local Motion Transformer
Pattern Recognition, 2024 (IF 7.5)
Boeun Kim, Jungho Kim, Hyung Jin Chang, Tae-Hyun Oh
Semi-Supervised Image Captioning by Adversarially Propagating Labeled Data
Dong-Jin Kim, Tae-Hyun Oh, Jinsoo Choi, In So Kweon
(Journal extension of “Image Captioning with Very Scarce Supervised Data: Adversarial Semi-Supervised Learning Approach,” EMNLP, 2019)

Overcoming Client Data Deficiency in Federated Learning by Exploiting Unlabeled Data on the Server
Jae-Min Park, Won-Jun Jang, Tae-Hyun Oh, Si-Hyeon Lee
The Devil in the Details: Simple and Effective Optical Flow Synthetic Data Generation
Kwon Byung-Ki, Kim Sung-Bin, Tae-Hyun Oh
Label Efficient Learning Methods for Computer Vision Applications
IEIE Transactions on Smart Processing & Computing (TSPC), 2024 (Invited paper)
Moon Ye-bin, Tae-Hyun Oh
* Haedong Best Paper Award 2024
Toward Interactive Sound Source Localization: Better Align Sight and Sound!
Arda Senocak, Hyeonggon Ryu, Junsik Kim, Tae-Hyun Oh, Hanspeter Pfister, Joon Son Chung
CLIP-Actor-X: Text-driven 4D Human Avatar Generation via Cross-modal Synthesis-through-Optimization
Under review
Kim Youwang*, Taehyun Byun*, Kim Ji-Yeon, Sungjoon Choi, Tae-Hyun Oh

ConfBALD: Deep Bayesian Active Learning against Confusing Classes
Under review
Chunsan Hong, Dogyun Kim, ByungHee Cha, Bohyung Kim, Junsik Kim, Tae-Hyun Oh
COARA: Efficient Correlation-Aware Uncertainty Modeling in Hand Pose Estimation
Under review
Lee Chae-Yeon*, Nam Hyeon-Woo*, Tae-Hyun Oh (*equal contribution)
2023
Conferences
TextManiA: Enriching Visual Feature by Text-driven Manifold Augmentation
Moon Ye-bin, Jisoo Kim, Hongyeob Kim, Kilho Son, Tae-Hyun Oh
* Presented in Workshop on Workshop on Foundation Model in conjunction with CVPR 2023.
* Presented in Workshop on MMFM: Multi-Modal Foundation Models, in conjunction with ICCV 2023.
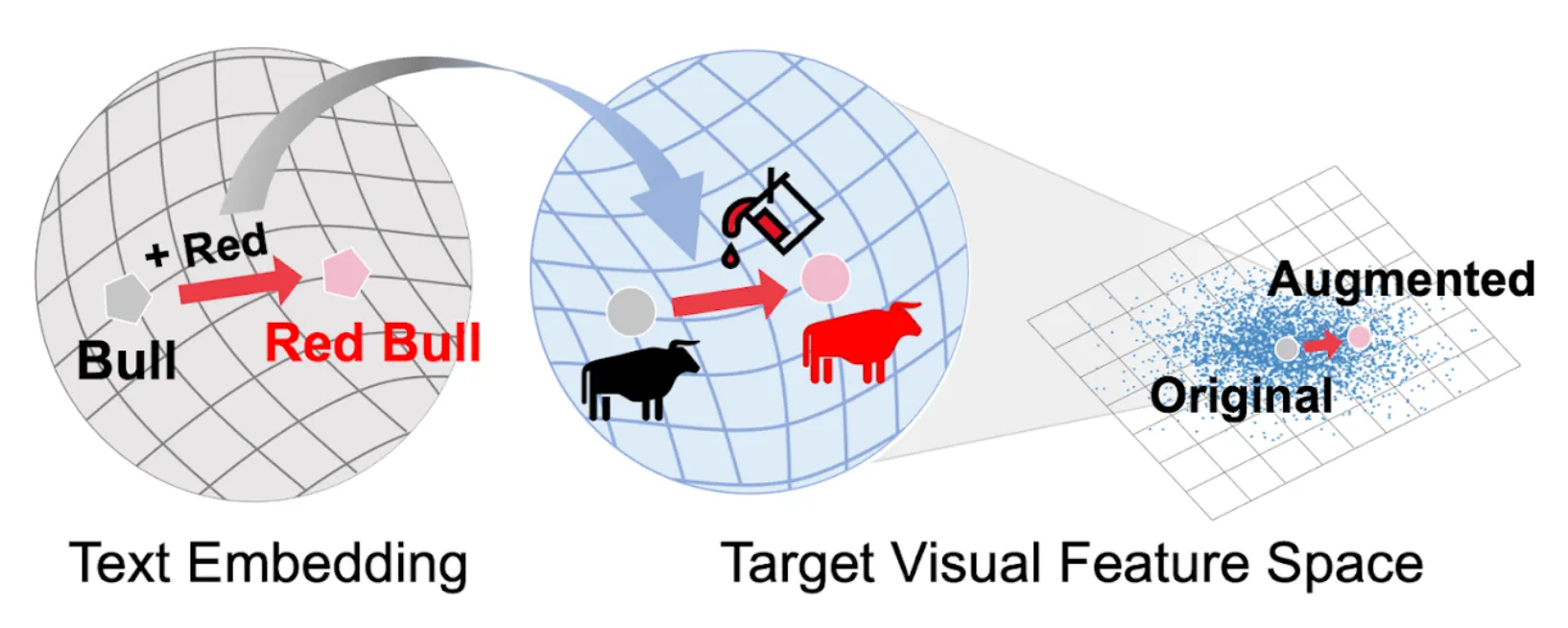
Scratching Visual Transformer's Back with Uniform Attention
Nam Hyeon-Woo, Kim Yu-Ji, Byeongho Heo, Dongyoon Han, Seong Joon Oh, Tae-Hyun Oh
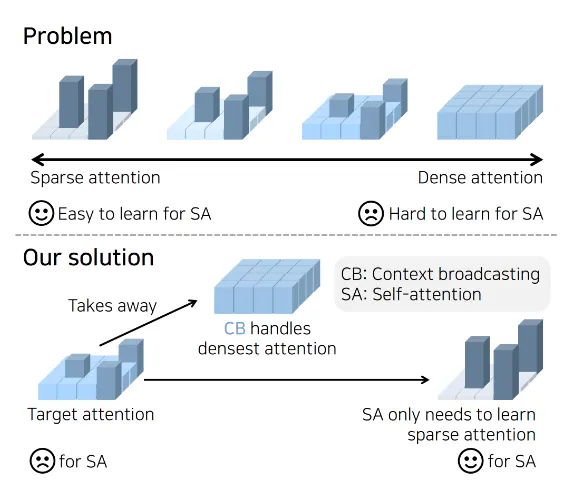
Sound Source Localization is All about Cross-Modal Alignment

Sound to Visual Scene Generation by Audio-to-Visual Latent Alignment
Kim Sung-Bin, Arda Senocak, Hyunwoo Ha, Andrew Owens, Tae-Hyun Oh
* Media coverage: covered by Yonhap News (연합뉴스), SBS, and many local media.
* Invited paper talk in Workshop on Sound and Sight, in conjunction with CVPR 2023.
* Presented in Workshop on AI4CC: AI for Content Creation Workshop, in conjunction with CVPR 2023.
* Presented in Workshop on AV4D: Visual learning of sounds in spaces, in conjunction with ICCV 2023.
DFlow: Learning to Synthesize Better Optical Flow Datasets via a Differentiable Pipeline
Kwon Byung-Ki, Nam Hyeon-Woo, Kim Ji-Yun, Tae-Hyun Oh
* Bronze Award, HumanTech Paper Award by Samsung
FPGA-Based Accelerator for Rank-Enhanced and Highly-Pruned Block-Circulant Neural Networks
Haena Song, Jongho Yoon, Dohun Kim, Eunji Kwon, Tae-Hyun Oh, Seokhyeong Kang
* Bronze Award, HumanTech Paper Award by Samsung
Learning Few-shot Segmentation from Bounding Box Annotations
Byeolyi Han, Tae-Hyun Oh
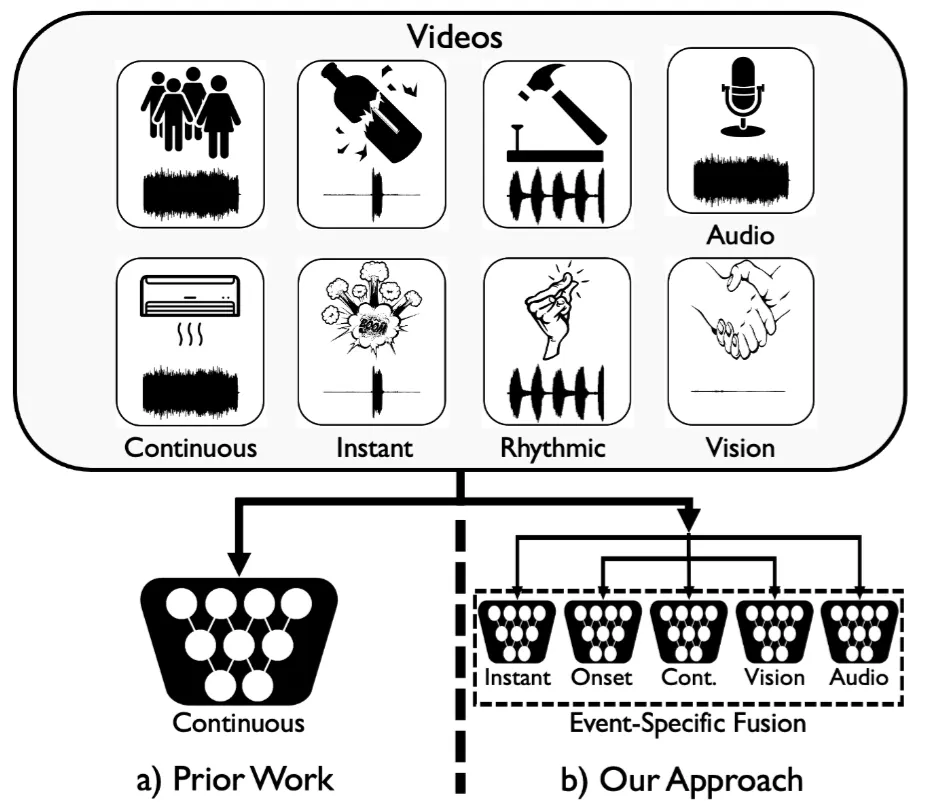
Event-Specific Audio-Visual Fusion Layers: A Simple and New Perspective on Video Understanding
Arda Senocak, Junsik Kim, Tae-Hyun Oh, Dingzeyu Li, In So Kweon
Prefix Tuning for Automated Audio Captioning
IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP) 2023 [Project Page] [Paper] [arXiv]
Minkyu Kim*, Kim Sung-Bin*, Tae-Hyun Oh (*equal contribution)
* Selected as Oral presentation
* Media coverage: covered by Yonhap News (연합뉴스), SBS, and many local media.
Unsupervised Pre-training for Data-Efficient Text-to-Speech on Low Resource Languages
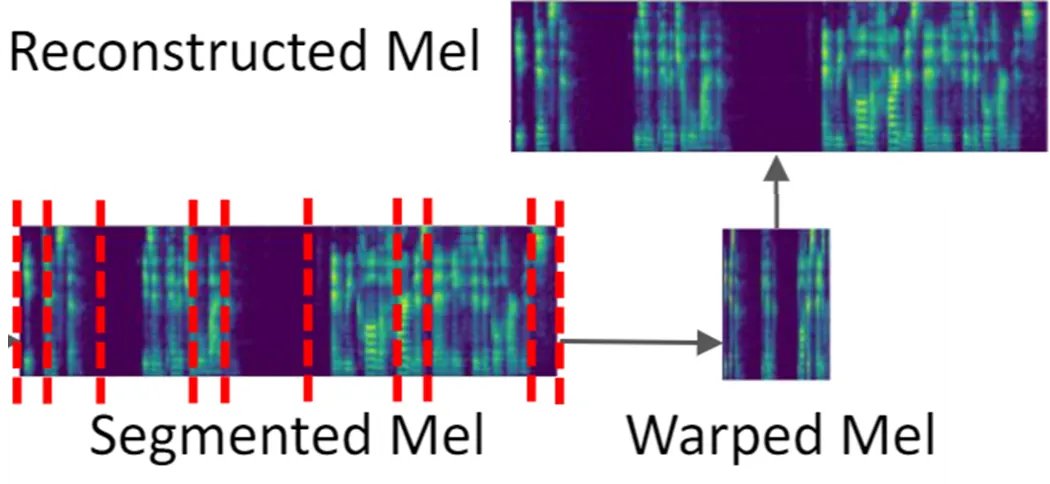
Automatic Tuning of Loss Trade-offs without Hyper-parameter Search in End-to-End Zero-Shot Speech Synthesis
Seongyeon Park, Bohyung Kim, Tae-Hyun Oh
Mask-KLT: Sub-pixel Accurate Directional Motion Estimation by Stripe Masking
Hyunwoo Ha, Tae-Hyun Oh
Text-driven Human Avatar Generation by Neural Re-parameterized Texture Optimization
IEEE International Conference on Computer Vision Workshop (ICCV workshop) 2023
(Workshop on AI for 3D Content Creation)
Kim Youwang, Tae-Hyun Oh

Multimodal Laughter Reasoning with Language Models
IEEE International Conference on Computer Vision Workshop (ICCV workshop) 2023
(Workshop on Multi-Modal Foundation Models)
Lee Hyun, Kim Sung-Bin, Seungju Han, Yougjae Yu, Tae-Hyun Oh
Exploiting Synthetic Data for Data Imbalance Problems: Baselines from a Data Perspective
IEEE International Conference on Computer Vision Workshop (ICCV workshop) 2023 [arXiv]
(Workshop on Multi-Modal Foundation Models)
Moon Ye-Bin*, Nam Hyeon-Woo*, Wonseok Choi, Nayeong Kim, Suha Kwak, Tae-Hyun Oh
Enhancing Classification Accuracy on Limited Data via Unconditional GAN
IEEE International Conference on Computer Vision Workshop (ICCV workshop) 2023
(Workshop on Representation Learning with Very Limited Images)
Chunsan Hong, ByungHee Cha, Bohyung Kim, Tae-Hyun Oh
Spatio-Temporally Consistent Face Mesh Reconstruction on Videos
IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPR workshop) 2023
(Workshop on 3DMV: Learning 3D with Multi-View Supervision)
Kim Youwang, Lee Hyun*, Kim Sung-Bin*, Suekyeong Nam, Janghoon Ju, Tae-Hyun Oh
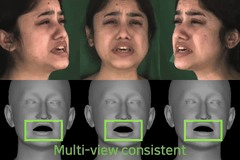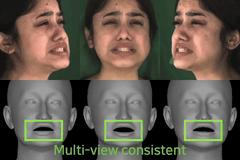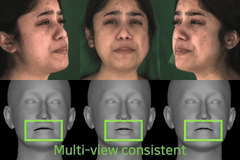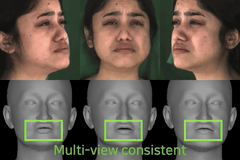
Revisiting Deep Video Motion Magnification for Real-time applications
IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPR workshop) 2023
(Workshop on Vision-based InduStrial InspectiON)
Hyunwoo Ha*, Oh Hyun-Bin*, Kim Jun-Seong, Kwon Byung-Ki, Kim Sung-Bin, Ji-Yun Kim, Sung-Ho Bae, Tae-Hyun Oh
MinDVPS: Minimal Model for Depth-aware Video Panoptic Segmentation
IEEE Conference on Computer Vision and Pattern Recognition Workshop (CVPR workshop) 2023
(Workshop on Vision Centric Autonomous Driving)
Kim Ji-Yeon, Oh Hyun-Bin, Dahun Kim, Tae-Hyun Oh
Journals
An Iterative Method for Unsupervised Robust Anomaly Detection under Data Contamination
IEEE Transactions on Neural Networks and Learning Systems (TNNLS), 2023 (IF 14.255)
Minkyung Kim, Jongmin Yu, Junsik Kim, Tae-Hyun Oh, Jun Kyun Choi
Multi-stage Adaptive Rank Statistic Pruning for Lightweight Human 3D Mesh Recovery Model
Dong Hun Ryou, Kim Youwang, Tae-Hyun Oh
Joint Video Super-Resolution and Frame Interpolation via Permutation Invariance
Jinsoo Choi, Tae-Hyun Oh
2022
Conferences
CLIP-Actor: Text-Driven Recommendation and Stylization for Animating Human Meshes
Kim Youwang*, Kim Ji-Yeon*, Tae-Hyun Oh (*equal contribution)
* Grand Prize (Minister’s award) in the 15th Electronic Times ICT Paper Awards 2023
* Qualcomm Innovation Award 2022
* Also, presented in Workshop on AI4CC: AI for Content Creation Workshop, in conjunction with CVPR 2023.
HDR-Plenoxels: Self-Calibrating High Dynamic Range Radiance Fields
Kim Jun-Seong*, Kim Yu-Ji*, Moon Ye-Bin, Tae-Hyun Oh (*equal contribution)
* Also, presented in Workshop on 3DMV: Learning 3D with Multi-View Supervision, in conjunction with CVPR 2023.
Cross-Attention of Disentangled Modalities for 3D Human Mesh Recovery with Transformers
Junhyeong Cho, Kim Youwang, Tae-Hyun Oh

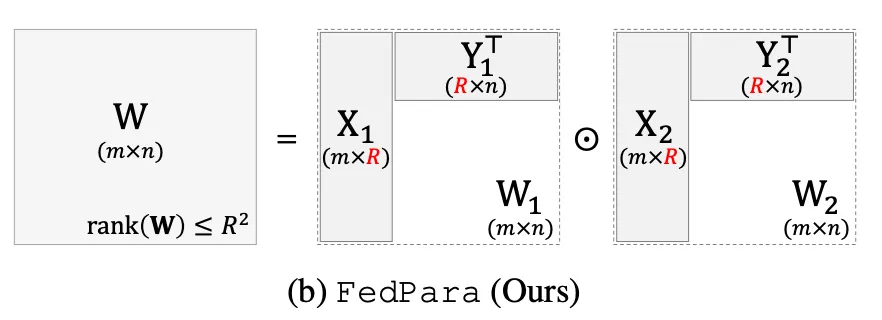
FedPara: Low-Rank Hadamard Product For Communication-Efficient Federated Learning
Nam Hyeon-Woo, Moon Ye-Bin, Tae-Hyun Oh
* Qualcomm Innovation Award 2021
* Best Poster Award (Gold), POSTECH-Naver AI Day 2022
Speech De-warping: Unsupervised Pre-training for Data-Efficient Text-to-Speech on Low Resource Languages
International Conference on Machine Learning Workshop (ICML workshop) 2022
Myungseo Song, Seongyeon Park, Bohyung Kim, Tae-Hyun Oh
* Accepted as a contributed talk (oral presentation)
FICGAN: Facial Identity Controllable GAN for De-identification
Yonghyun Jeong, Jooyoung Choi, Sungwon Kim, Youngmin Ro, Tae-Hyun Oh, Doyeon Kim, Heonseok Ha, Sungroh Yoon
Journals
Dense Relational Image Captioning via Multi-task Triple-Stream Networks
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2022 (IF 24.314) [arXiv] [IEEEXplore] [Code]
Dong-Jin Kim, Tae-Hyun Oh, Jinsoo Choi, In So Kweon
* Qualcomm Innovation Award 2019
Robust and Efficient Estimation of Relative Pose for Cameras on Selfie Sticks
Kyungdon Joo, Hongdong Li, Tae-Hyun Oh, In So Kweon
Neural-Network-Based Automated Synthesis of Transformer Matching Circuits for RF Amplifier Design
Dongyoon Lee, Gibeom Shin, Seunghoon Lee, Kyunghwan Kim, Tae-Hyun Oh, Ho-Jin Song
2021
Conferences
Unified 3D Mesh Recovery of Humans and Animals by Learning Animal Exercise
Kim Youwang, Kim Ji-Yeon, Kyungdon Joo, Tae-Hyun Oh

CDS: Cross-Domain Self-supervised Pre-training
Donghyun Kim, Kuniaki Saito, Tae-Hyun Oh, Bryan Plummer, Stan Sclaroff, Kate Saenko
Distilling Global and Local Logits with Densely Connected Relations
International Conference on Computer Vision (ICCV) 2021 [PDF]
Youmin Kim, Jinbae Park, YounHo Jang, Muhammad Ali, Tae-Hyun Oh, Sung-Ho Bae
Monocular Reconstruction of Neural Face Reflectance Fields
Mallikarjun B R, Ayush Tewari, Tae-Hyun Oh, Tim Weyrich, Bernd Bickel, Hans-Peter Seidel, Hanspeter Pfister, Wojciech Matusik, Mohamed Elgharib, Christian Theobalt
MDARTS: Multi-objective Differentiable Neural Architecture Search
Design Automation and Test in Europe (DATE) 2021 (Accept. rate < 25%) [PDF]
Sunghoon Kim, Hyunjeong Kwon, Eunji Kwon, Youngchang Choi, Tae-Hyun Oh, Seokhyeong Kang
Supervoxel Attention Graphs for Long-Range Video Modeling
Winter Conference on Applications of Computer Vision (WACV) 2021 [PDF]
Yang Wang, Gedas Bertasius, Tae-Hyun Oh, Abhinav Gupta, Minh Hoai Nguyen, Lorenzo Torresani
Journals
Lightweight Speaker Recognition in Poincaré Spaces
Jieun Lee*, Kim Sung-Bin*, Seokhyeong Kang, Tae-Hyun Oh (*equal contribution)
Learning to Localize Sound Sources in Visual Scenes: Analysis and Applications
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 2021 [IEEEXplore] [Dataset] [Code(PyTorch)Featured by Seamless]
Arda Senocak, Tae-Hyun Oh, Junsik Kim, Ming-Hsuan Yang, In So Kweon
* Qualcomm Innovation Award 2018
2020
Conferences
Listen to Look: Action Recognition by Previewing Audio
Ruohan Gao, Tae-Hyun Oh, Kristen Grauman, Lorenzo Torresani
Linear RGB-D SLAM for Atlanta World
Kyungdon Joo, Tae-Hyun Oh, Francois Rameau, Jean-Charles Bazin, In So Kweon
Globally Optimal Relative Pose Estimation for Camera on a Selfie Stick
Kyungdon Joo, Hongdong Li, Tae-Hyun Oh, Yunsu Bok, In So Kweon
Journals
Globally Optimal Inlier Set Maximization for Atlanta World Understanding
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 2020 [Project Page] [IEEE Xplore]
Kyungdon Joo, Tae-Hyun Oh, In So Kweon, Jean-Charles Bazin
2019
Conferences
Speech2Face: Learning the Face Behind a Voice
Tae-Hyun Oh*, Tali Dekel*, Changil Kim*, Inbar Mosseri, William T. Freeman, Michael Rubinstein, Wojciech Matusik (*equal contribution)
* Media coverage: covered by Gizmodo, Tech Xplore, Futurism, Daily Mail, and others.
Neural Inverse Knitting: From Images to Manufacturing Instructions
Alexandre Kaspar*, Tae-Hyun Oh*, Liane Makatura, Petr Kellnhofer, Jacqueline Aslarus, Wojciech Matusik (*equal contribution)
* Media coverage: covered by more than 20 media (BBC News, Fortune, Engadget, ...).
Dense Relational Captioning: Triple-Stream Networks for Relationship-Based Captioning
Dong-Jin Kim, Tae-Hyun Oh, Jinsoo Choi, In So Kweon
* Qualcomm Innovation Award 2019
Noise-tolerant Audio-visual Online Person Verification using an Attention-based Neural Network Fusion
Suwon Shon, Tae-Hyun Oh, James Glass
Variational Prototyping-Encoder: One-Shot Learning with Prototypical Images
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2019 [PDF] [Project Page]
Junsik Kim, Tae-Hyun Oh, Seokju Lee, Fei Pan, In So Kweon
Visuomotor Understanding for Representation Learning of Driving Scenes
Seokju Lee, Junsik Kim, Tae-Hyun Oh, Yongseop Jeong, Donggeun Yoo, Stephen Lin, In So Kweon
Image Captioning with Very Scarce Supervised Data: Adversarial Semi-Supervised Learning Approach
Dong-Jin Kim, Jinsoo Choi, Tae-Hyun Oh, In So Kweon
Journals
High-fidelity Depth Upsampling using Self-learning Framework
Inwook Shim, Tae-Hyun Oh, In So Kweon
Robust and Globally Optimal Manhattan Frame Estimation in Near Real Time
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 2019 [Code and Project page] [arXivIEEE Xplore]
Kyungdon Joo, Tae-Hyun Oh, Junsik Kim, In So Kweon
Gradient-based Camera Exposure Control for Outdoor Mobile Platforms
IEEE Transactions on Circuits and Systems for Video Technology (TCSVT) 2019 [Project Page] [IEEE XplorearXiv]
Inwook Shim, Tae-Hyun Oh, Joon-Young Lee, Dong-Geol Choi, Jinwook Choi, In So Kweon
2018
Conferences
Learning-based Video Motion Magnification
European Conference on Computer Vision (ECCV) 2018 [PDF] [Project Page] [Video Results] [Oral Presentation]
Tae-Hyun Oh*, Ronnachai Jaroensri*, Changil Kim, Mohamed Elgharib, Frédo Durand, William T. Freeman, Wojciech Matusik (*equal contribution)
* Accepted as a full oral paper (2.3% acceptance rate)
Co-domain Embedding using Deep Quadruplet Network for Unseen Traffic Sign Recognition
Junsik Kim , Seokju Lee , Tae-Hyun Oh , In So Kweon
Disjoint Multi-task Learning between Heterogeneous Human-centric Tasks
Dong-Jin Kim, Jinsoo Choi, Tae-Hyun Oh, Youngjin Yoon, In So Kweon
* Accepted as a full oral paper
Contextually Customized Video Summaries via Natural Language
Jinsoo Choi, Tae-Hyun Oh, In So Kweon
Learning to Localize Sound Source in Visual Scenes
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2018 [PDF] [Code & Dataset] [Featured by Seamless]
Arda Senocak, Tae-Hyun Oh, Junsik Kim, Ming-Hsuan Yang, In So Kweon
* Qualcomm Innovation Award 2018
Globally Optimal Inlier Set Maximization for Atlanta Frame Estimation
Kyungdon Joo, Tae-Hyun Oh, In So Kweon, Jean-Charles Bazin
Part-based Player Identification using Deep Convolutional Representation and Multi-scale Pooling
Arda Senocak, Tae-Hyun Oh, Junsik Kim, In So Kweon
On Learning Associations of Faces and Voices
Changil Kim, Hijung Valentina Shin, Tae-Hyun Oh, Alexandre Kaspar, Mohamed Elgharib, Wojciech Matusik
Journals
Fast Randomized Singular Value Thresholding for Low-rank Optimization
Tae-Hyun Oh, Yasuyuki Matsushita, Yu-Wing Tai, In So Kweon
* Gold Prize (Acceptance Rate 0.8%), 21th HumanTech Paper Award by Samsung
Semantic Soft Segmentation
Yağiz Aksoy, Tae-Hyun Oh, Sylvain Paris, Marc Pollefeys, Wojciech Matusik
* Covered by international news media (BBC News, MIT CSAIL news, etc.) and featured as Tech. paper preview by SIGGRAPH
2017
Journals
A Closed-Form Solution to Rotation Estimation for Structure from Small Motion
Hyowon Ha, Tae-Hyun Oh, In So Kweon
Conferences
Weakly-and Self-Supervised Learning for Content-aware Deep Image Retargeting
Donghyeon Cho, Jinsun Park, Tae-Hyun Oh, Yu-Wing Tai, In So Kweon
* Selected as spotlight (2.61% acceptance rate)
Personalized Cinemagraphs using Semantic Understanding and Collaborative Learning
{Tae-Hyun Oh, Kyungdon Joo}*, Neel Joshi, Baoyuan Wang, In So Kweon, Sing Bing Kang (*equal contribution)
2016
Journals
Human Attention Estimation for Natural Images: An Automatic Gaze Refinement Approach
Jinsoo Choi, Tae-Hyun Oh, In So Kweon
Partial Sum Minimization of Singular Values in Robust PCA: Algorithm and Applications
Tae-Hyun Oh, Yu-Wing Tai, Jean-Chales Bazin, Hyeongwoo Kim, In So Kweon
Conferences
Robust and Globally Optimal Manhattan Frame Estimation in Near Real Time
{Tae-Hyun Oh, Kyungdon Joo}*, Junsik Kim, In So Kweon (*equal contribution)
Video-Story Composition via Plot Analysis
IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2016 [PDF] [Presentation] [Dataset]
Jinsoo Choi, Tae-Hyun Oh, In So Kweon
* Selected as spotlight (9.7% acceptance rate)
A Pseudo-Bayesian Algorithm for Robust PCA
Tae-Hyun Oh, David Wipf, Yasuyuki Matsushita, In So Kweon
2015
Journals
Pseudo-Bayesian Robust PCA: Algorithms and Analysis
Tae-Hyun Oh, David Wipf, Yasuyuki Matsushita, In So Kweon
Robust High Dynamic Range Imaging by Rank Minimization
Tae-Hyun Oh, Joon-Young Lee, Yu-Wing Tai, In So Kweon
An Autonomous Driving System for Unknown Environments using a Unified Map
Inwook Shim, Jongwon Choi, Seunghak Shin, Tae-Hyun Oh, Unghui Lee, Byungtae Ahn, Dong-Geol Choi, David Hyunchul Shim, In So Kweon
* Qualcomm Innovation Award 2013
* Youl-Jeong award (5th rank) from the Hyundai Motors Autonomous Vehicle Challenge 2012
Conferences
Fast Randomized Singular Value Thresholding for Nuclear Norm Minimization
Tae-Hyun Oh, Yasuyuki Matsushita, Yu-Wing Tai, In So Kweon
Line Meets As-Projective-As-Possible Image Stitching With Moving DLT
Kyungdon Joo, Namil Kim, Tae-Hyun Oh, In So Kweon
* Selected as the Top 10% paper
A Multi-View Structured-Light System for Highly Accurate 3D Modeling
International Conference on 3D Vision (3DV) 2015
Hyowon Ha, Tae-Hyun Oh, In So Kweon
2014
Conferences
Balanced Optical Flow Refinement by Bidirectional Constraint
IEEE International Conference on Image Processing (ICIP) 2014
Jongwon Choi, Hyeongwoo Kim, Tae-Hyun Oh, In So Kweon
Cost-Aware Depth Map Estimation for Lytro Camera
IEEE International Conference on Image Processing (ICIP) 2014
Min Jung Kim, Tae-Hyun Oh, In So Kweon
A Two Phase Approach for Pedestrian Detection
Workshop in conjunction with the 12th Asian Conference on Computer Vision (ACCVW) 2014
SoonMin Hwang, Tae-Hyun Oh, In So Kweon
2013
Conferences
Partial Sum Minimization of Singular Values in RPCA for Low-Level Vision
Tae-Hyun Oh, Hyeongwoo Kim, Yu-Wing Tai, Jean-Chales Bazin, In So Kweon
High Dynamic Range Imaging by a Rank-1 Constraint
Tae-Hyun Oh, Joon-Young Lee, In So Kweon
Hierarchical 3D Line Restoration based on Angular Proximity in Structured Environments
Kyungdon Joo, Tae-Hyun Oh, Hyeongwoo Kim, In So Kweon
2012
Conferences
Autonomous Homing based on Laser-Camera Fusion System
Dong-Geol Choi, Inwook Shim, Yunsu Bok, Tae-Hyun Oh, In So Kweon
A Tensor Voting Approach for Multi-View 3D Scene Flow Estimation and Refinement
Jaesik Park, Tae-Hyun Oh, Jiyoung Jung, Yu-Wing Tai, In So Kweon
Real-Time Motion Detection based on Discrete Cosine Transform
Tae-Hyun Oh, Joon-Young Lee, In So Kweon
