Two papers have been accepted to IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2023. WACV is the premier international computer vision event comprising the main conference and several co-located workshops and tutorials.
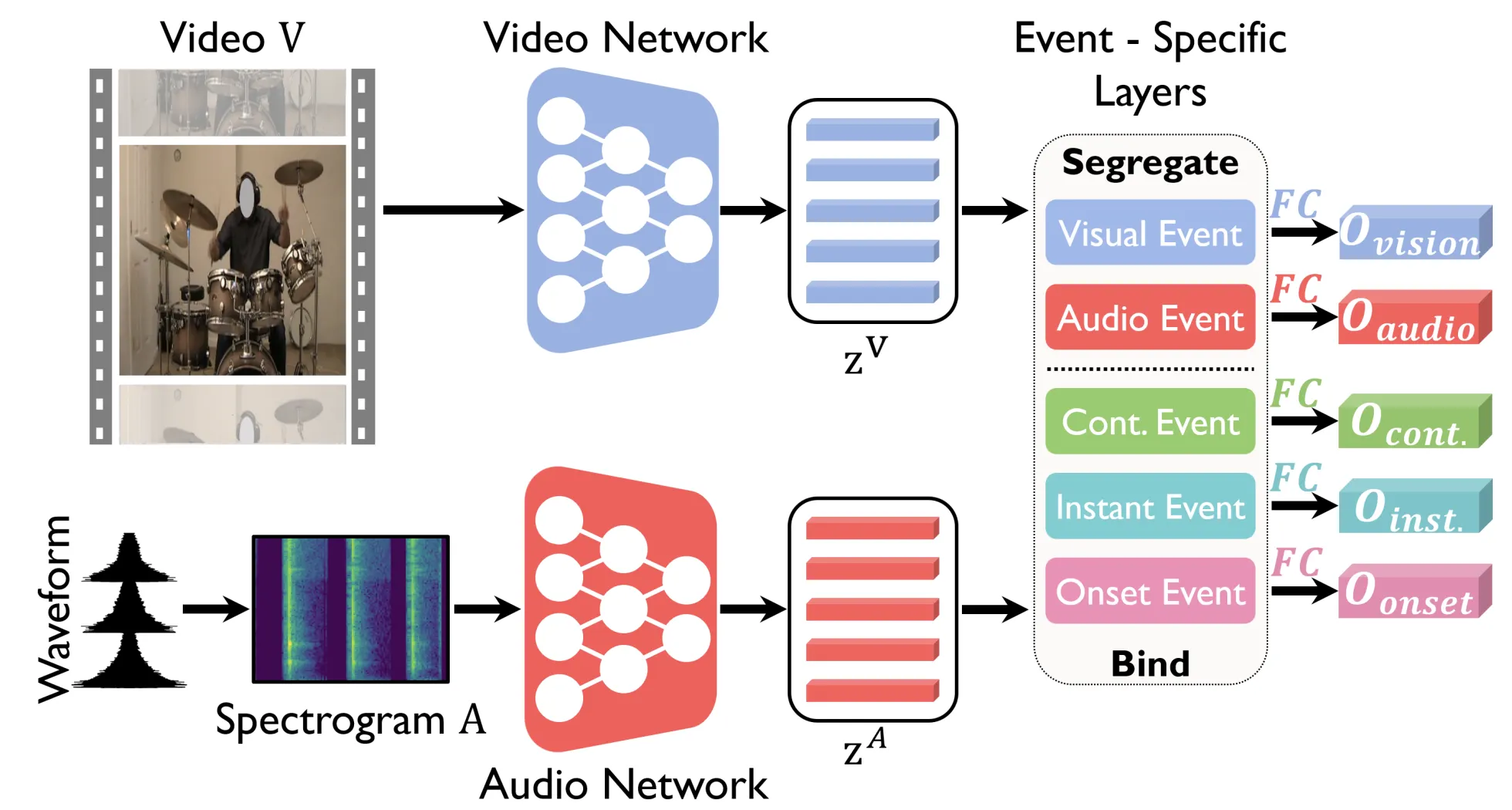
Title: Event-Specific Audio-Visual Fusion Layers: A Simple and New Perspective on Video Understanding
Authors: Arda Senocak, Junsik Kim, Tae-Hyun Oh, Dingzeyu Li, In So Kweon
Human brain is continuously inundated with the multisensory information and their complex interactions coming from the outside world at any given moment. Such information is automatically analyzed by binding or segregating in our brain. While this task might seem effortless for human brains, it is extremely challenging to build a machine that can perform similar tasks since complex interactions cannot be dealt with single type of integration but requires more sophisticated approaches. In this paper, we propose a new model to address the multisensory integration problem with individual event-specific layers in a multi-task learning scheme. Unlike previous works where single type of fusion is used, we design event-specific layers to deal with different audio-visual relationship tasks, enabling different ways of audio-visual formation. Experimental results show that our event-specific layers can discover unique properties of the audio-visual relationships in the videos. Moreover, although our network is formulated with single labels, it can output additional true multi-labels to represent the given videos. We demonstrate that our proposed framework also exposes the modality bias of the video data category-wise and dataset-wise manner in popular benchmark datasets.
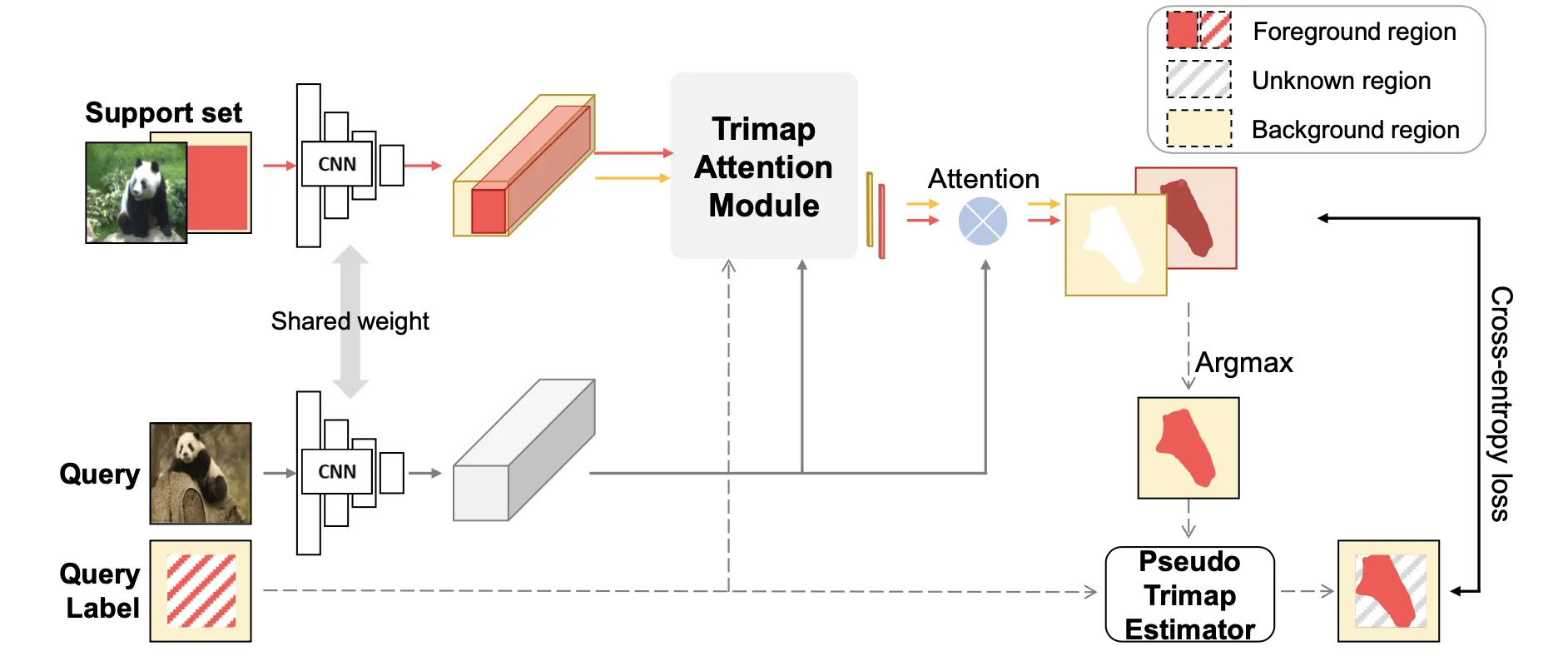
Title: Learning Few-shot Segmentation from Bounding Box Annotations
Authors: Byeolyi Han, Tae-Hyun Oh
We present a new weakly-supervised few-shot semantic segmentation setting and a meta-learning method for tackling the new challenge. Different from existing settings, we leverage bounding box annotations as weak supervision signals during the meta-training phase, i.e., more label-efficient. Bounding box provides a cheaper label representation than segmentation mask but contains both an object of interest and a disturbing background. We first show that meta training with bounding boxes degrades recent few-shot semantic segmentation methods, which are typically meta-trained with full semantic segmentation supervisions. We postulate that this challenge is originated from the impure information of bounding box representation. We propose a pseudo trimap estimator and trimap-attention based prototype learning to extract clearer supervision signals from bounding boxes. These developments robustify and generalize our method well to noisy support masks at test time. We empirically show that our method consistently improves performance. Our method gains 1.4% and 3.6% mean-IoU over the competing one in full and weak test supervision cases, respectively, in the 1-way 5-shot setting on Pascal-5i.